Normalisasi vs Standarisasi

Normalisasi atau standarisasi? adalah pertanyaan yang tak pernah habis di dunia machine learning, khususnya bagi pendatang baru, atau kadang bahkan yang sudah lama pun lupa bagaimana keduanya berbeda termasuk implementasinya. Pertanyaan ini mirip seperti bubur diaduk atau tidak diaduk? Pertanyaan abadi di dunia ini. Oke abaikan masalah bubur, mari kita uraikan sedikit di artikel singkat ini tentang kedua metode scaling data tersebut.
Apa bedanya?
Normalisasi pada dasarnya adalah teknik perubahan skala yang mana kita merubah nilai dari data kedalam skala diantara 0–1. Teknik ini biasa juga disebut sebagai Min-Max scaling :
Persamaan diatas adalah formula dari normalisasi, dengan Xmax adalah nilai maximum dari interval data yang dimiliki, dan Xmin adalah nilai minimumnya.
Sedangkan standarisasi, adalah tehnik lain dalam melakukan perubahan skala, dimana data yang dimiliki akan diubah sehingga memiliki rata rata = 0 (terpusat) dan standar deviasi = 1.
Dari persamaan diatas, bisa kita lihat bahwa X adalah nilai data asli, μ adalah nilai rata rata dari data yang ada, dan σ adalah nilai standar deviasinya.
Bingungkan? Lebih bingung mana dari bahas bubur diaduk vs tidak diaduk? Agar kita tidak bingung, mari kita langsung ke contoh penggunaannya.
Perbedaan Penggunaan
Pertama, biasanya penggunaan normalisasi dilakukan pada data yang memang mengikuti distribusi normal, sedangkan standarisasi sebaliknya. Standarisasi sangat membantu ketika data tersebut tidak terdistribusi normal secara gaussian. Sama seperti kata kunci utamanya yaitu ‘standar’, penggunaan standarisasi memang untuk membuat kisaran nilai menjadi ‘standar’ dengan standar deviasi dan rata rata dari data mula yang dimiliki.
Kedua, standarisasi tidak memiliki jangkauan nilai sebagaimana normalisasi yang memiliki nilai 0–1. Bahkan jika kita memiliki data outlier, data tersebut tidak akan terganggu oleh standarisasi yang kita lakukan.
Tapi pada implementasinya, penggunaan keduanya dikembalikan lagi kepada si pengguna, dan tentu tergantung pada masalah yang ada di algoritma atau sistem pembelajaran dari model yang sedang kita buat. Tidak ada aturan baku kapan kita harus memakai salah satunya, kita selalu dapat mencoba pada data yang dimiliki dan melihat pengaruhnya pada model.
Oh iya hampir lupa, perlu diingat, jika kita berniat merubah data outlier menjadi normal, maka kedua metode scaling diatas baik itu standarisasi atau normalisasi bukan solusinya. Umumnya, ketika data otulier dilakukan scaling, angkanya memang berubah dengan skala baru, namun posisinya tetap sama sebagai outlier. Jadi jika memang ingin ‘menormalkan’ data, hal itu bisa dilakukan dengan metode transformasi, bukan scaling. Bahasan tranformasi mungkin akan dibahas ditulisan terpisah.
Implementasi dengan Python
Mari langsung saja kita praktikan kedua hal tersebut dengan sederhana, saya mengambil data dari gapminder dimana data yang saya ambil hanya ‘life expectancy’ yang kemudian dilihat per negara. Sebagai catatan, alasan data tersebut digunakan adalah hanya untuk memudahkan kita membayangkan apa yang terjadi di antara normalisasi dan standarisasi, dengan mengabaikan konteks datanya.
Kalau begitu, mari kita langsung saja plot distribusi normalnya
Sekilas terlihat bahwa setiap negara memiliki nilai tengah (mean) yang bervariasi dengan visualisasi yang ditunjukan diatas, dimana nilai ‘life expectancy’ ada dikisaran 20–80 tahun, dengan Afrika yang memiliki nilai mean terkecil dibanding yang lainnya yaitu di sekitar 45 tahun.
Sekarang mari kita lihat bagaimana efek dari normalisasi dan standarisasi terhadap paramater life_exp tersebut:
Code:
# Feature Scaling with Standarization
from sklearn.preprocessing import StandardScalersc = StandardScaler()
X_scaler = sc.fit_transform(data_wide) #data_wide is table name
Hasil:
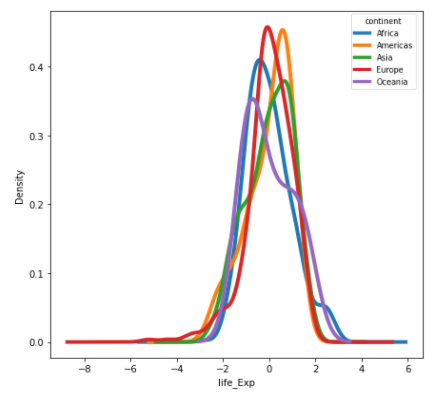
Terlihat bahwa standarisasi seperti sedang memusatkan semua data di satu titik yang sama pada interval -8 sampai dengan 6, bahkan nilai mean Afrika yang sebelumnya terlihat berbeda, sekarang memiliki distribusi yang identik dengan negara lainnya.
Lalu pada normalisasi terlihat pada gambar berikut:
Code:
# Feature Scaling with Normalization
from sklearn.preprocessing import MinMaxScalermin_max_scaler = MinMaxScaler()
X_minmax = min_max_scaler.fit_transform(data_wide) #data_wide is table name
Hasil:

Pada Normalisasi, skala data berubah menjadi interval 0-1 (pada gambar dilebihkan 0.5, menjadi -0.5 sampai 1.5). Pola distribusi memang sekilas mirip dengan data asli, namun sebetulnya berbeda karena nilai mean dari setiap negara sudah berubah. Bisa kembali perhatikan pada Africa dimana posisinya berada di kanan Oceania, padahal di data asli sebaliknya. Artinya nilai mean Africa berubah menjadi lebih besar dibanding Oceania.
Dari plot distribusi yang telah dilakukan, sekarang bisa kita pahami seperti apa perubahan data yang terjadi pada normalisasi dan standarisasi. Umumnya, selain menggunakan plot dan melihat distribusinya, dampak dari 2 scaling tadi dapat juga dilihat dari boxplot, itu sangat direkomendasikan sebagai pelengkap.
Lantas jika kembali ke pertanyaan mana yang lebih baik? Tergantung kasus dan modelnya, tipsnya masih sama: coba saja! Sebetulnya masih banyak contoh data lain yang lebih tepat untuk dilakukan normalisasi atau standarisasi dibanding ‘life expectancy’, apalagi jika data tersebut memiliki skala yang berbeda di setiap parameternya.
Pada kesempatan lainnya mungkin akan coba saya bahas bagaimana dampak kedua hal tersebut pada kasus lain, termasuk terhadap model, dan juga metode scaling lain seperti robust scaler. Pada tulisan ini, kita cukupkan sampai disini, mari makan bubur diaduk dan tidak diaduk!
